여러가지 합성곱 신경망 레이어들 - InceptionV1(Googlenet)
인셉션이 나오기 전
과학자들은 ImageNet Large-Scale Visual Recognition Challenge(ILSVRC) 에서 좋은 성과를 보여주려고 딥러닝에 대해 연구하던 중 여러가지 레이어들이 나왔다.
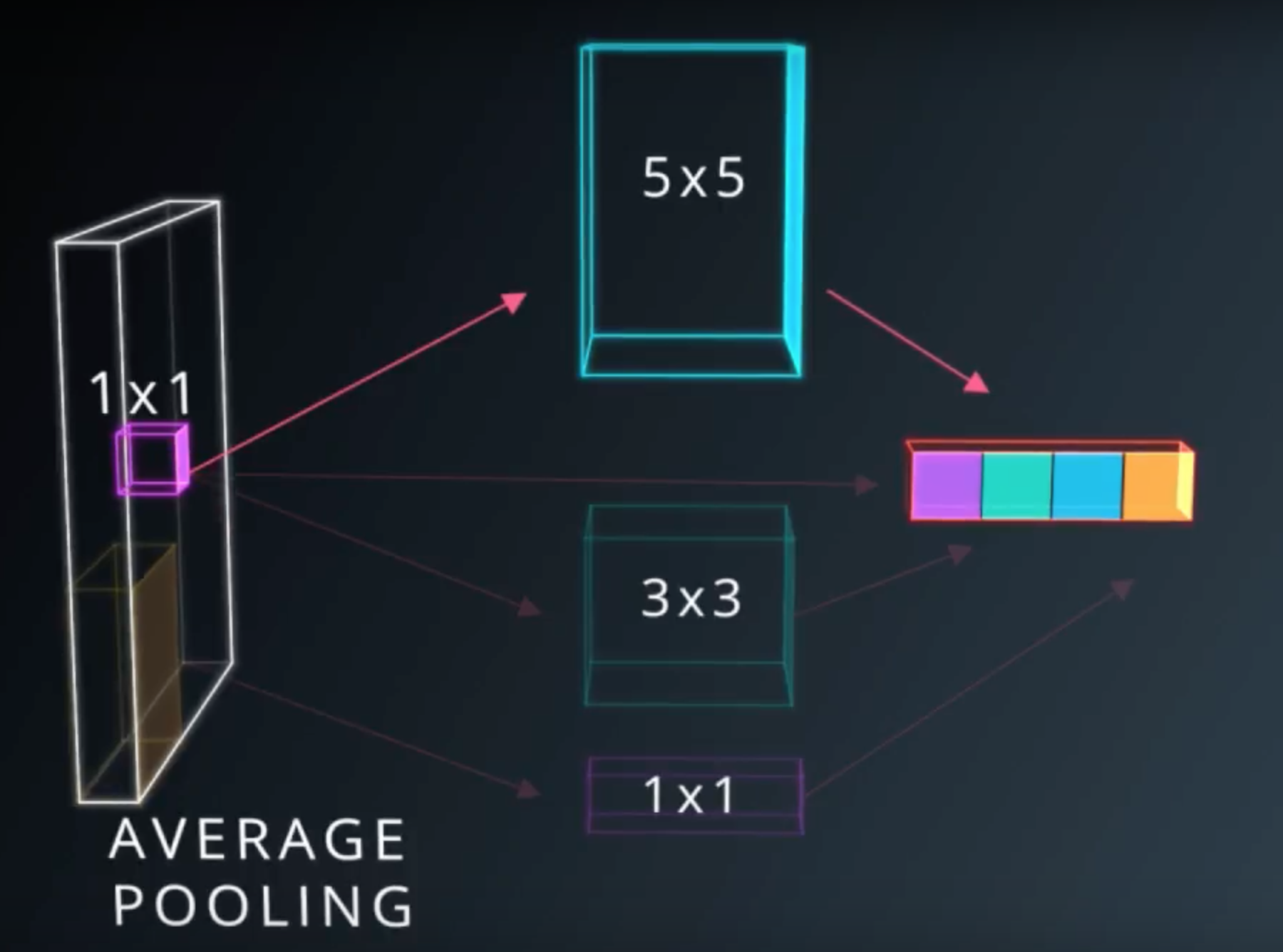
- 연산도 간단하고 픽셀마다의 피쳐를 계산해서 최대한 정보를 보존시켜준다는 1x1 Convolution(Conv1x1)
- 연산량을 대폭 줄여주어 cost도 절약되고 overfitting도 줄여주는 MaxPooling
- 이외 여러가지 커널 사이즈들의 Convolution layer들(3x3, 5x5)
물론 각 레이어마다 신경망의 정확도를 높이는 데 기여를 하기는 했지만 어느 쪽이 좀 더 효과적인지에 대해 고민하고 있었는데…
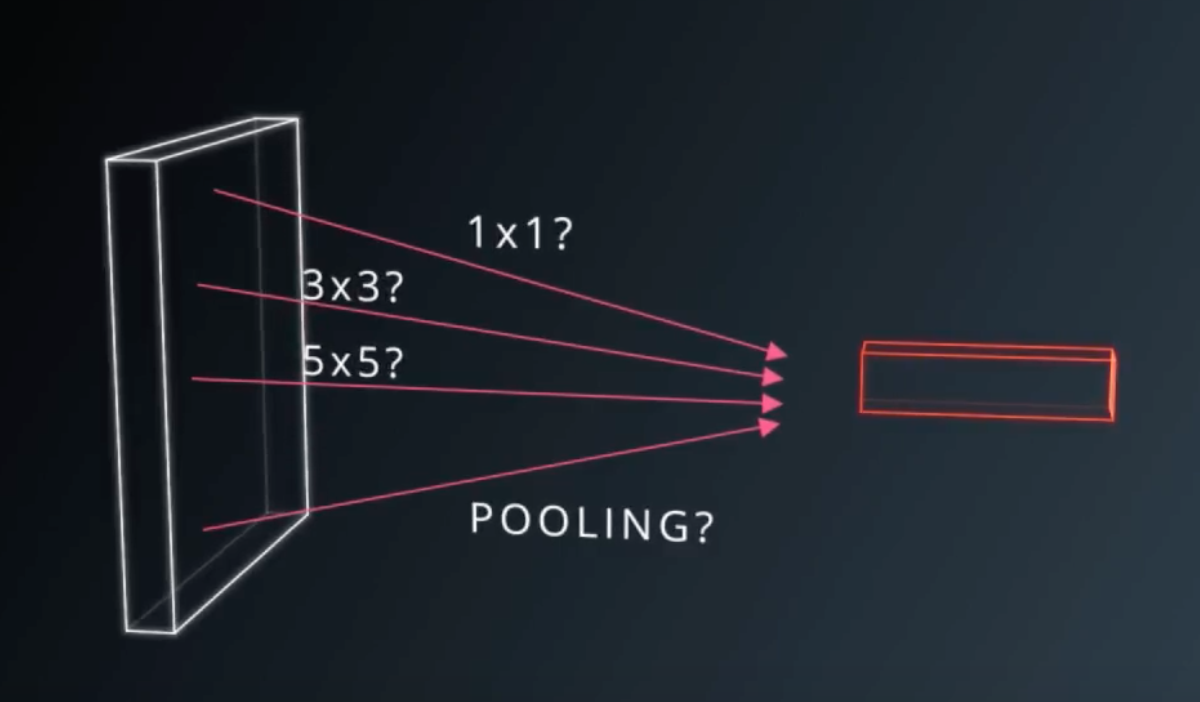
구글의 연구자들은 고민을 하다가 Min Lin의 논문인 Network in Network를 읽게 되고 2010년에 개봉한 영화인 인셉션 meme(짤) “we need to go deeper”를 떠올리며 그냥 레이어들을 합쳐버리기로 결심한다.
“codenamed Inception, which derives its name from the Network in network paper by Lin et al [12] in conjunction with the famous “we need to go deeper” internet meme [1]” ― Inventors of inception module

구조
naive version

from tensorflow.contrib.keras.python import keras as keras
from keras.layers import Conv2D, MaxPooling2D, AveragePooling2D, concatenate, Input
from keras import models
def inception_block(input_layer, filter1=64, filter2=128, filter3=32, activation='relu'):
conv1x1 = Conv2D(filter1, kernel_size=(1,1), padding='same', activation=activation)(input_layer)
conv3x3 = Conv2D(filter2, kernel_size=(3,3), padding='same', activation=activation)(input_layer)
conv5x5 = Conv2D(filter3, kernel_size=(5,5), padding='same', activation=activation)(input_layer)
pooling = MaxPooling2D((3,3), strides=(1,1), padding='same')(input_layer)
#Average pooling은 평균값을 구하여 줄여주나 연산량을 많이 요구한다.
#pooling = AveragePooling2D((3,3), strides=(1,1), padding='same')(input_layer)
output_layer = concatenate([conv1x1, conv3x3, conv5x5, pooling])
return output_layer
shape = (224,224,3)
inputs = Input(shape)
inception_1 = inception_block(inputs, 64, 128, 32)
# output_layer = Dense(64)(inception_1)
model = models.Model(input=inputs, output=output_layer)
dimension reduction
Convolution1x1 레이어를 이용하여 dimension을 줄여준다. 이를 실행한 결과 AlexNet보다 12배만큼 적은 패러미터로 훈련시킬 수 있었다.

from tensorflow.contrib.keras.python import keras as keras
from keras.layers import Conv2D, MaxPooling2D, AveragePooling2D, concatenate
from keras import models
def inception_block_dim_reduce(input_layer, filter1, filter2, filter3, reduce1, reduce2, pool_proj, activation='relu', pull=False):
conv1x1 = Conv2D(filter1, kernel_size=(1,1), padding='same', activation=activation)(input_layer)
conv3x3_reduce = Conv2D(reduce1, kernel_size=(1,1), padding='same', activation=activation)(input_layer)
conv3x3 = Conv2D(filter2, kernel_size=(3,3), padding='same', activation=activation)(conv3x3_reduce)
conv5x5_reduce = Conv2D(reduce2, kernel_size=(1,1), padding='same', activation=activation)(input_layer)
conv5x5 = Conv2D(filter3, kernel_size=(5,5), padding='same', activation=activation)(conv5x5_reduce)
pooling = MaxPooling2D((3,3), strides=(1,1), padding='same')(input_layer)
pool_proj = Conv2D(pool_proj, kernel_size=(1,1), padding='same', activation=activation)(pooling)
output_layer = concatenate([conv1x1, conv3x3, conv5x5, pool_proj])
# Googlenet exracts pool_proj in order to ensemble in three cases
if pull == True:
return output_layer, pool_proj
return output_layer
shape = (224,224,3)
inputs = Input(shape)
inception_reduce_1 = inception_block(inputs, 64, 128, 32)
# output_layer = Dense(64)(inception_reduce_1)
model = models.Model(input=inputs, output=output_layer)
GoogLeNet
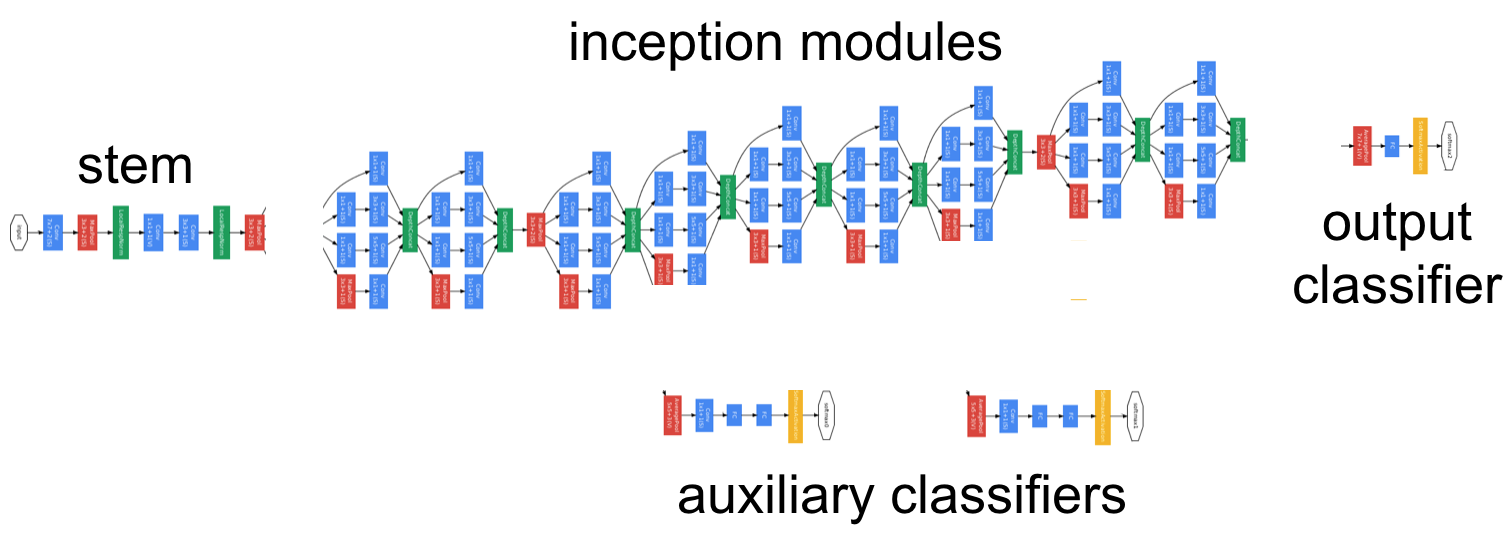
GoogLeNet은 4가지 컴포넌트들로 이루어져 있다.
stem
이 레이어는 다른 인셉션 모듈과 달리 순차적으로 패러미터들을 전파시킨다. stem이라는 이름은 후에 서술되는 v2,v3부터 언급되는데, 인셉션 모듈들만 사용한 모델 대신 stem 레이어를 넣었을 때 문제가 생긴다는 저자의 언급으로 보아, 사라질 위기에 처해있다.
inception modules
이 레이어는 GoogLeNet을 만드는 데 있어서 가장 기초적인 블록이다. 합성곱 신경망과 pooling 레이어들로 이루어져 있으며, 각 케이스마다 수행된 뒤 depth를 축으로 합쳐진다. conv1x1으로 패러미터를 축소시킬 경우 적은 패러미터로 효과적인 학습을 가능하게 한다.
auxiliary classifiers
GoogLeNet의 구조가 깊어서 그런지 vanishing gradient 문제를 걱정하던 연구진들은 중간 레이어들에 나오는 feature들로 구분하면 마지막 레이어보다 bias가 높은 판단을 내릴 것이라고 가정한 뒤 auxilary classifier를 두어 loss function에 위 구분자들의 loss값을 일정 부분 포함시킨다. 그러나 테스트 과정에서는 쓰지 않는다.
output classifiers
최종 단계로서 이미지를 인식하는 부분을 담당한다. average pooling으로 패러미터를 줄인 뒤 softmax로 각 클래스일 확률을 구한다.
Implementation
결론
- padding에서 ‘same’ 옵션은 서로 다른 케이스의 레이어들을 합칠 때 쓰인다.
- 짤을 보며 영감을 얻을 수 있다.
Reference
다음
전 구글 엔지니어이자 케라스 창시자인 Francois Chollet은 좀 더 효율적으로 패러미터를 생성하는 합성곱 신경망에 대해 고려하게 된다. 이에 ‘Separable Convolution’을 발견하게 되는데…
여러가지 합성곱 신경망 레이어들 - Xception
앞으로 연재 계획
1~2개월에 한번씩 올립니다. 그동안 신경망 예제를 적용하여 성능을 비교해보거나, 만든 프로젝트를 적용한 케이스가 있다면 케라스 코리아에 공유해주셨으면 합니다.

Comments